Contents
はじめに
ここではパフォーマンスに関連する様々な事項について解説します。
内容は主にプログラマ向けとなります。
CPUに依存
MagicaClothはUnity DOTS(Data-Oriented Technology Stack)で動作します。
そのためシミュレーションの性能はCPUに完全に依存します。
逆にGPUは一切利用しません。
また、DOTSはマルチスレッドに対応しているためCPUのコア数(スレッド数)が多いほど並列実行が可能なのでパフォーマンスが良くなります。
モバイル端末での性能
ただしAndroid/iPhoneで利用する場合は少し注意が必要です。
モバイル端末のCPUは大きなコア構成と小さな低出力コア構成の2つで形成されていることが一般的です。
これをBig-Little構成と呼びます。
例えば端末が8コアのCPUでもBig4/Little4などに振り分けられている場合がほとんどです。
この場合は(4-4コア)などと表記されます。
そしてUnityはこのうちBigコアでしかDOTSが実行されません。
そのため上記の端末の場合はDOTSで利用できるのは8コアの内の4コアのみとなります。
この点に注意してください。
デスクトップPCのCPUではこのような問題は起こりません。
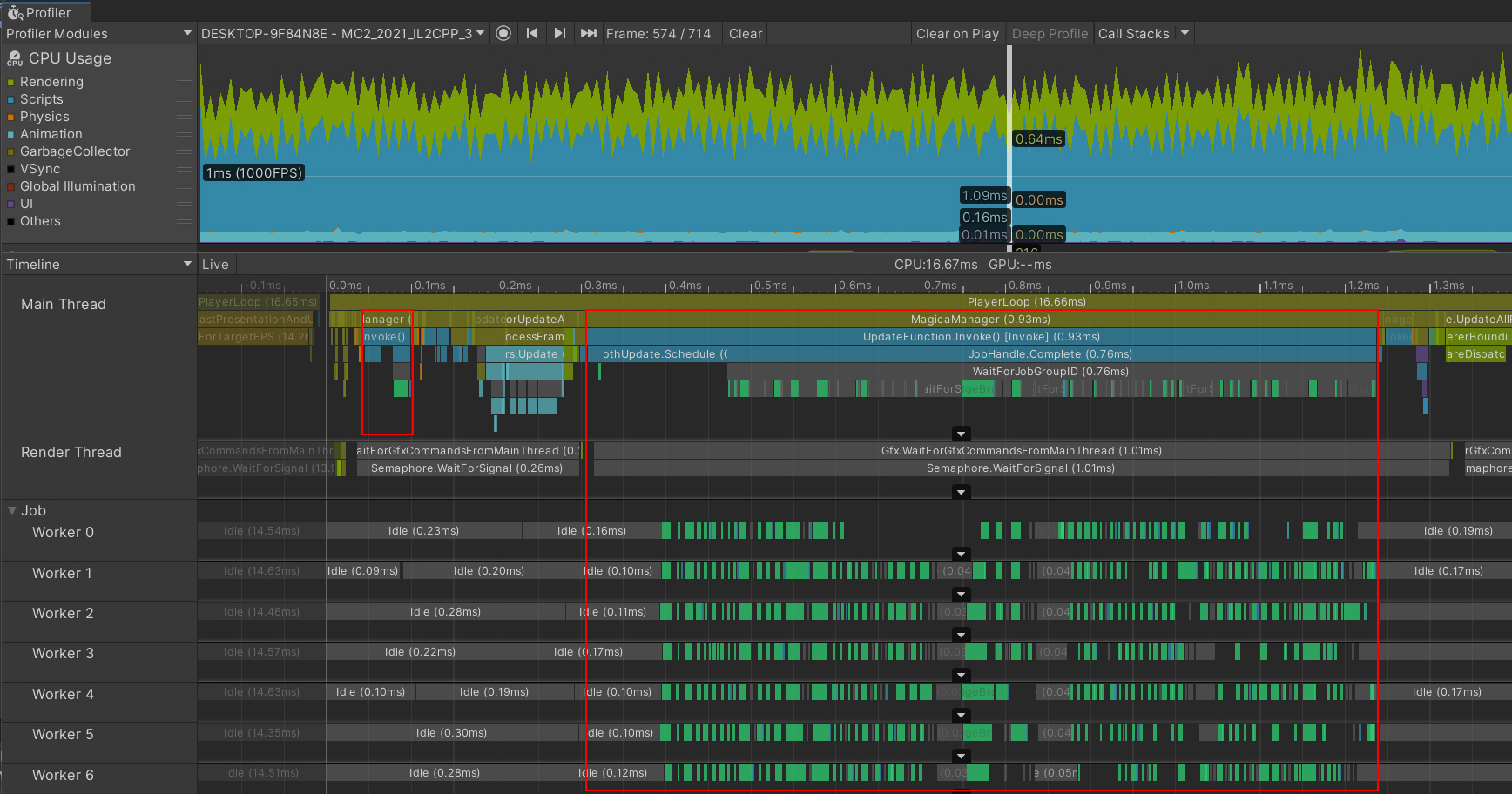
プロファイラでの確認
シミュレーションの負荷はUnityのプロファイラ機能で簡単に確認することが可能です。
プロファイラではMagicaManagerのブロックとしてタイムラインに表示されます。
マルチスレッドの状況は同じくJobの項目で確認することが可能です。
クロスデータの作成と実行
MagicaClothではシミュレーションを行うために様々なデータが必要です。
これをクロスデータと呼びます。
そしてクロスデータは実行時に要求に応じてその場で生成されます。
このクロスデータの作成にはかなりの計算処理が必要なため通常10ms~50msほどかかります。
この作成処理はバックグラウンドスレッドで実行されるためメインスレッドにはほとんど影響はありません。
また複数のクロスデータは別々のスレッドで作成されるため並列実行されます。
しかし、シミュレーションはこのクロスデータが完成するまで待たなければなりません。
そのため実際にキャラクターが生成されてからシミュレーションが開始するまでに数フレームの遅延が発生します。
エディタ実行時の注意
MagicaClothが利用するBurstとJobSystemはビルド時と比較してエディタ実行時では負荷が高くなります。
そのためエディタ実行時のプロファイラはビルド時と同じでは無いことに留意してください。
これは次の要因によるものです。
BurstのJITコンパイラ
Burstはエディタでの実行時に限り、実行時コンパイル(Just-In-Time Compiler)されます。
これはプレイが開始されてから行われるため、MagicaClothが最初に利用される場合には数百ms以上のコンパイル時間が発生します。
従ってエディタ環境ではプレイ後に最初のシミュレーションが開始するまでにかなりの遅延が発生します。
この問題はエディタ環境のみでビルド時には発生しません。
この問題を回避するには次のようにEnter Play Mode Optionsを利用してください。
これはPlayerSettingsのEditorタブにあります。

Enter Play Modeを利用することで実行を繰り返しても再度BurstがJITコンパイルされることが無くなります。
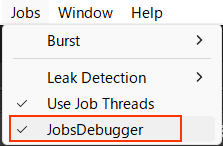
JobsDebuggerの負荷
エディタでは常にJobsDebuggerがJobの動作を監視しています。
そのためジョブの実行時間が通常より長くなり、またジョブとジョブの間に不自然な空白時間が発生したりとあまり良いことがありません。
そのため負荷が気になる場合は次のようにJobsDebuggerをOFFにしてください。
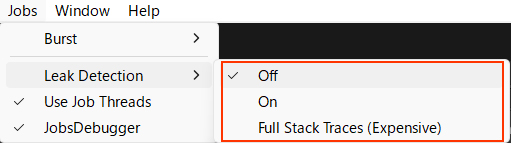
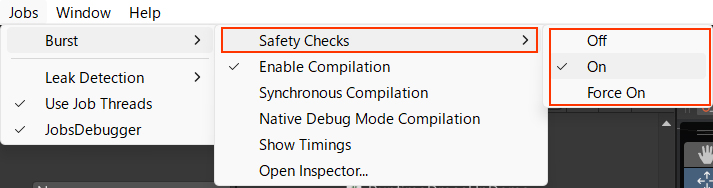
SafeCheckの負荷
同じくエディタ環境ではBurstの安全性の監視が行われています。
この負荷もそれなりに発生するため、気になる場合は次の2つのチェックをOFFにしてください。
エラーが報告されなくなるので注意
ただし上記のようにJobDebuggerとSafeCheckをOFFにするとBurst/Jobsのエラーが表示されなくなるので注意してください。
そのためMagicaClothの動作がおかしいと感じた場合はすべてのチェックをONに戻してエラーが発生していないかを確認するようにしてください。
ビルドでのテストを推奨
上記のようにエディタ実行時では様々な監視のためシミュレーションのパフォーマンスが下がります。
しかし、リリースビルドではこれらの監視がすべてなくなります。
そのため実際のパフォーマンスはビルドを行い実機で確認することが一番です。
ビルド時の注意
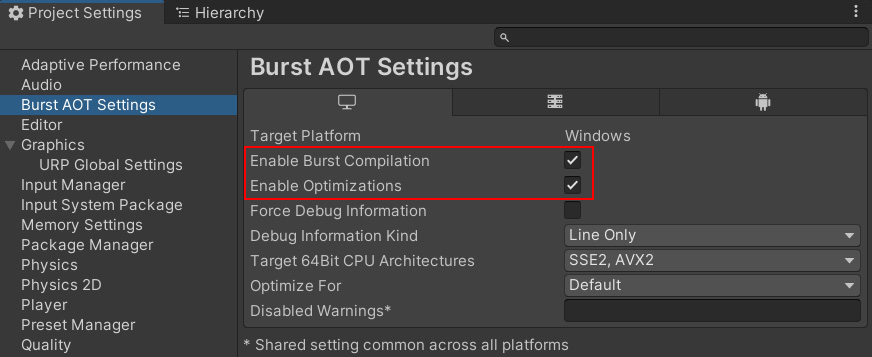
Burst AOT Settings
ビルド時にBurstを有効にすることを忘れないでください。
これはPlayerSettingsのBurst AOT Settingsから行います。
チェックを外すとBurstが無効な状態でビルドされますので注意してください。
通常は初期状態で有効化されています。
IL2CPPを推奨
ビルド時はIL2CPPを利用することを強く推奨します。
これはMonoに比べてC#の処理速度が大きく向上するためです。
処理負荷の一覧
ここではMagicaClothの機能の中でも特に負荷が高いものについて解説します。
負荷は★が多いほど高くなります。
クロスデータ構築方法
| 実行時構築(デフォルト) | ★★★ | 実行時構築ではクロスデータを利用時にその場で作成します。 このため初期化時の負荷が高くなります。 クロスデータはバックグラウンドで作成されますが、この処理もCPUを消費します。 |
| 事前構築 | ★ | 事前構築では編集時にクロスデータを作成してアセット化します。 そのため初期化の負荷が大きく下がります。 また、バックグラウンドでの処理もありません。 |
クロスタイプ
| MeshCloth | ★★★★ |
MeshClothはシミュレーション以外にプロキシメッシュのスキニングとレンダーメッシュへの書き戻しがあるためBoneClothに比べてかなり高負荷になります。 そのためモバイル端末での利用はパフォーマンスに注意してください。 |
| BoneCloth | ★ | BoneClothはとても軽量です。 殆どのケースにおいて大量に使用しても問題は起こりません。 |
衝突処理
| Self Collision | ★★★★★★★★★★ |
自己衝突はすべての機能の中で突出して負荷が高い処理です。 もしモバイル端末で利用する場合はできる限りプロキシメッシュの頂点数を減らしパフォーマンスに十分注意してください。 |
| Mutual collision | ★★★★★★★★ |
相互衝突は相手との衝突判定のみなので自己衝突に比べると少しだけ負荷が下がります。 ただし処理としては自己衝突と変わらないためこちらもパフォーマンスには十分注意してください。 |
| Edge Collision | ★★★★ |
エッジコリジョンはポイントコリジョンに比べると数倍負荷が高くなります。 ポイントコリジョンで問題がある場合のみ利用するように心がけてください。 |
| Point Collision | ★★ |
ポイントコリジョンは他のコリジョン判定に比べれば遥かに低負荷です。 |
| Backstop | ★ |
バックストップは少しの計算で済むため最も負荷が低いです。 |
シミュレーション周波数と最大更新回数
MagicaClothのシミュレーションは独自の時間管理によりUnityのフレーム更新とは異なるタイミングで実行されます。
これは図のようになり、フレームレートとは無関係に一定間隔で実行されています。
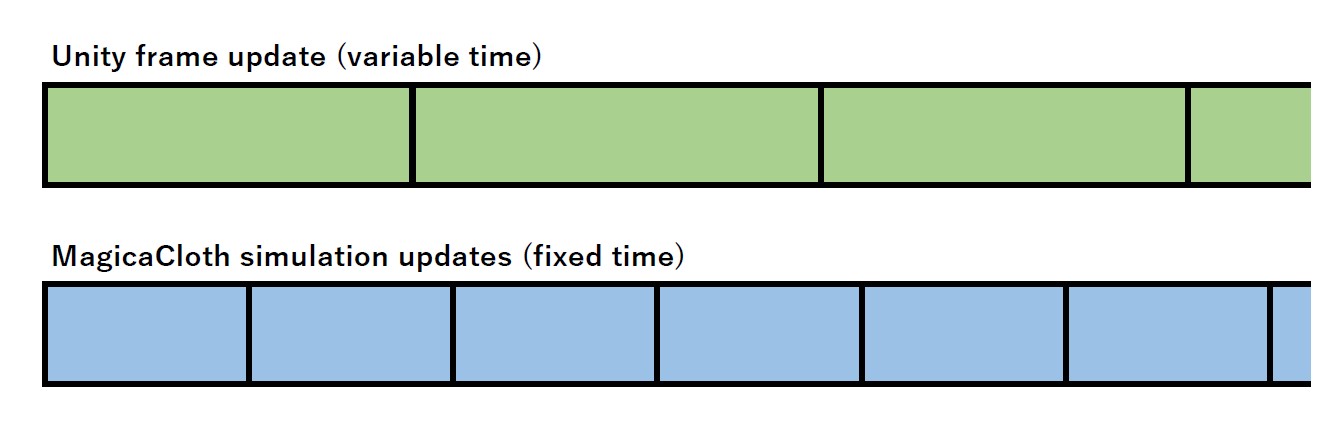
この一定の間隔をシミュレーション周波数と呼びます。
例えば周波数が90であれば1/90秒ごとにシミュレーションが更新されることになります。
これはUnityの物理エンジンの更新(FixedUpdate)とフレーム更新との関係と同じです。
MagicaClothでは初期値として周波数が90に設定されています。
つまり、シミュレーションは1秒間に90回更新されます。
また1フレームに実行できる最大のシミュレーション回数が設定されています。
これは過剰に負荷がかかった場合に無限にシミュレーションを繰り返さないようにするための安全機能です。
MagicaClothでは初期値として3回に設定されています。
仮に最大回数によりシミュレーションの実行が省略された場合は補間機能により位置が補われます。
この補間機能は単純であるためそれほど精度は高くありません。
そのためシミュレーションが省略された場合はアーティファクトが発生する可能性がある点に留意してください。
周波数とパフォーマンス
シミュレーション周波数はパフォーマンスに直結しています。
周波数を下げればシミュレーションの実行回数が減るためパフォーマンスが向上します。
しかし、周波数はシミュレーションの精度に大きく影響しています。
そのため、周波数を下げるとシミュレーションの精度も下がることになります。
周波数とシミュレーション精度はトレードオフの関係にあることを留意してください。
周波数と最大更新回数の変更
周波数と最大更新回数は2つの方法で変更が可能です。
変更はいつでも可能です。
API
スクリプトからはAPIにより変更が可能です。
MagicaSettings
システムの状態を変更するためにMagicaSettingsと呼ばれる専用のコンポーネントが用意されています。
このコンポーネントを利用することでコーディング無しに周波数と最大更新回数を変更できます。
設定方法はMagicaSettingsのドキュメントを参照してください。

周波数の動作影響
周波数を変更するとシミュレーション動作が若干変化します。
例えば周波数90で動きを調整したとしても、周波数を30や150にすると動きに変化が現れ完全には同一になりません。
これは周波数の変更によりパラメータの効果に若干の差異が発生するためです。
したがって、周波数の変更によりパラメータの再調整が必要になる場合があります。
設定例
ここではいくつかの設定事例について解説します。
パフォーマンス優先
パフォーマンスが重要な場合は周波数を60、最大更新回数を2に設定してみてください。
精度が少し落ちますがパフォーマンスが向上します。

固定フレームレート
もしゲームが60fpsなどの固定フレームレートで動作する場合はそれに合わせて周波数を設定する方法も有効です。
例えば周波数をfpsと同じ60にして最大更新回数を1に制限します。
これにより1フレームの負荷が安定します。

またゲームが30fpsで動作する場合は、周波数を60にして最大更新回数を2にするのも効果的です。
これにより1フレームで2回シミュレーションが更新され、30fpsであっても周波数60の精度が確保できます。

パフォーマンス最優先
もしパフォーマンスを最優先とする場合は周波数を30にして最大更新回数を1に設定してみてください。
これにより最大のパフォーマンスを得ることが可能です。
ただし精度がかなり落ちることに十分注意してください。
この設定はアーティファクトよりパフォーマンスを優先します。

カリングシステム
カリングとはカメラに描画されいないキャラクターやカメラから一定距離以上離れたキャラクターのシミュレーションを停止してパフォーマンスを向上させる機能です。

この機能は一人称視点のFPSやVRでのパフォーマンスが大きく向上します。
カリングはカメラカリングと距離カリングの2つの機能から構成されています。
詳しくはカリングシステムのドキュメントを参照してください。
キャラクターの配置
DOTSではTransformの読み書きについてもマルチスレッド化されています。
ただしこの恩恵を得るにはキャラクターの配置方法に注意が必要です。
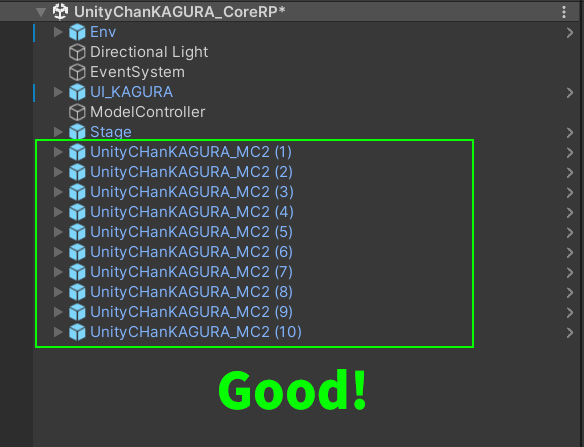
DOTSでは階層のルートに配置されたGameObjectグループごとにTransformの処理がマルチスレッド化されます。
次の例では10体のキャラクターがすべてルートに配置されているため、キャラクターごとにTransformの処理がマルチスレッドで実行されるようになります。
これが理想的な配置です。
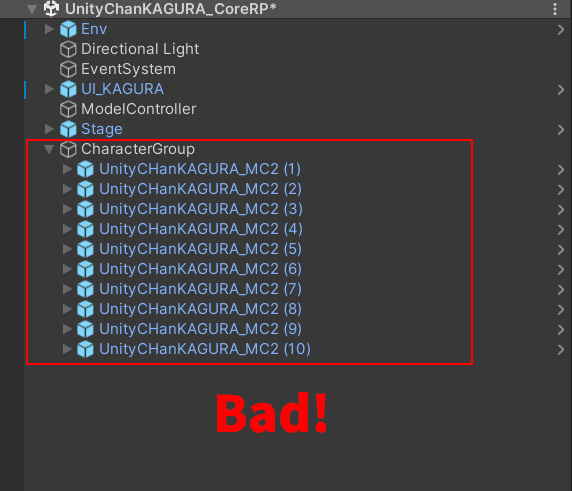
しかし次の例ではすべてのキャラクターが”CharacterGroup”オブジェクトの子として配置されています。
これはとても悪い例でTransformの処理が一切マルチスレッド化されません。
特にキャラクター数が多い場合はパフォーマンスの悪化が顕著に現れますので注意してください。
シミュレーションジョブ
ここではクロスシミュレーションがどのように実行されているかを解説します。
この項目はシミュレーション処理の最適化が行われたv2.14.0以降を前提にしています。
分割ジョブ
シミュレーション処理はジョブと呼ばれる処理単位に分割されて実行されます。
このジョブはプロファイラで確認することができます。
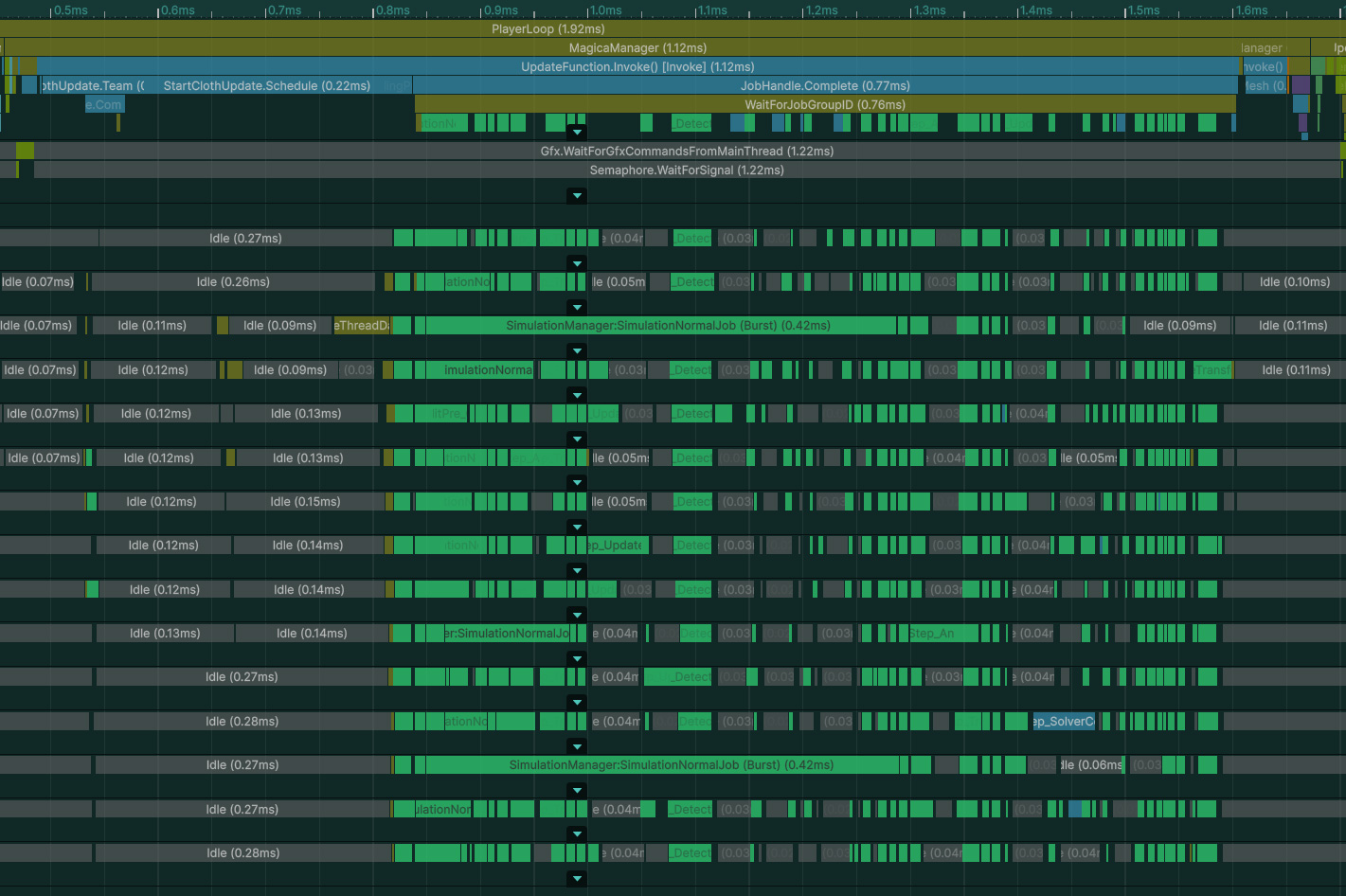
画像からわかるようにジョブはかなり細かく分割されています。
これは各処理の節目でデータの同期を行う必要があるからです。
この方法はCPUのコアを最大限活用できる利点がありますが、ジョブのスケジュール時間や同期のための待ち時間が増えるなどの欠点もありました。
一括ジョブ
そこでv2.14.0からはジョブを分割せずに一括で処理する機能が入りました。
一括ジョブでは1つのMagicaClothコンポーネントの処理が1つのジョブとして割り当てられます。
これにより、分割ジョブに比べて余計な同期時間などが無くなり速度が大きく向上します。
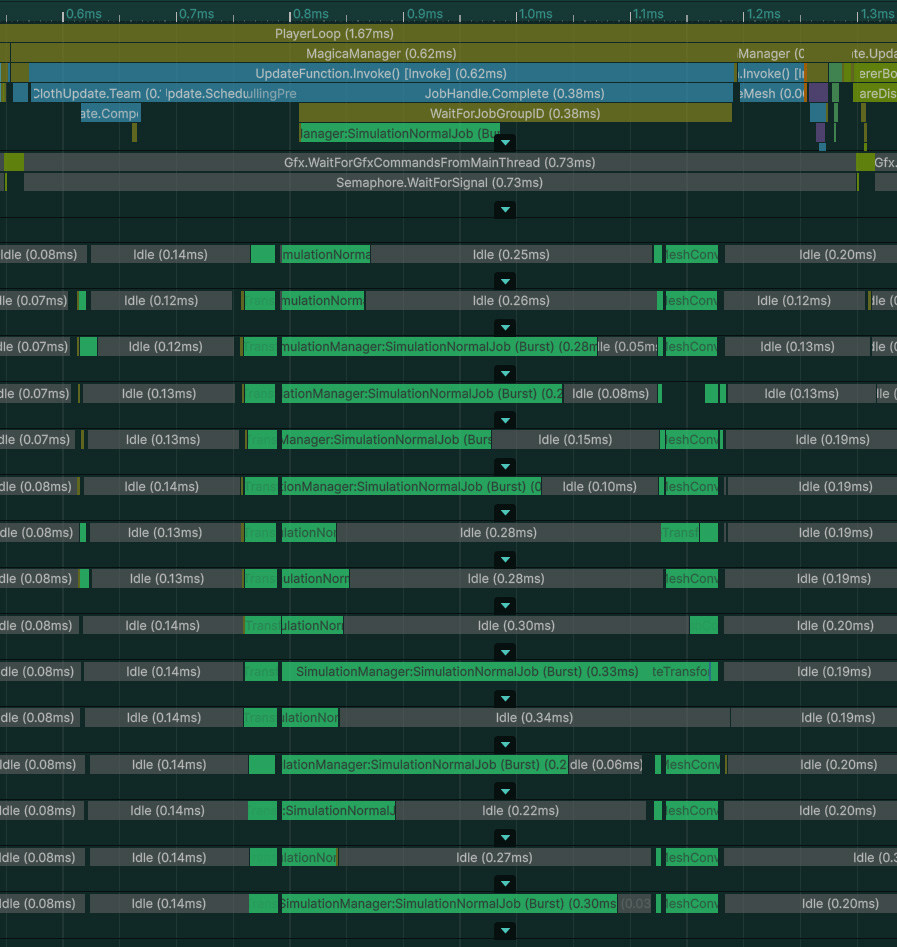
しかし、欠点もあります。
一括ジョブではジョブを分割しないため、スレッドによる分散処理が行えません。
その結果、処理が重いMagicaClothコンポーネントが1つあると、次のように全体の処理時間が伸びてしまいます。
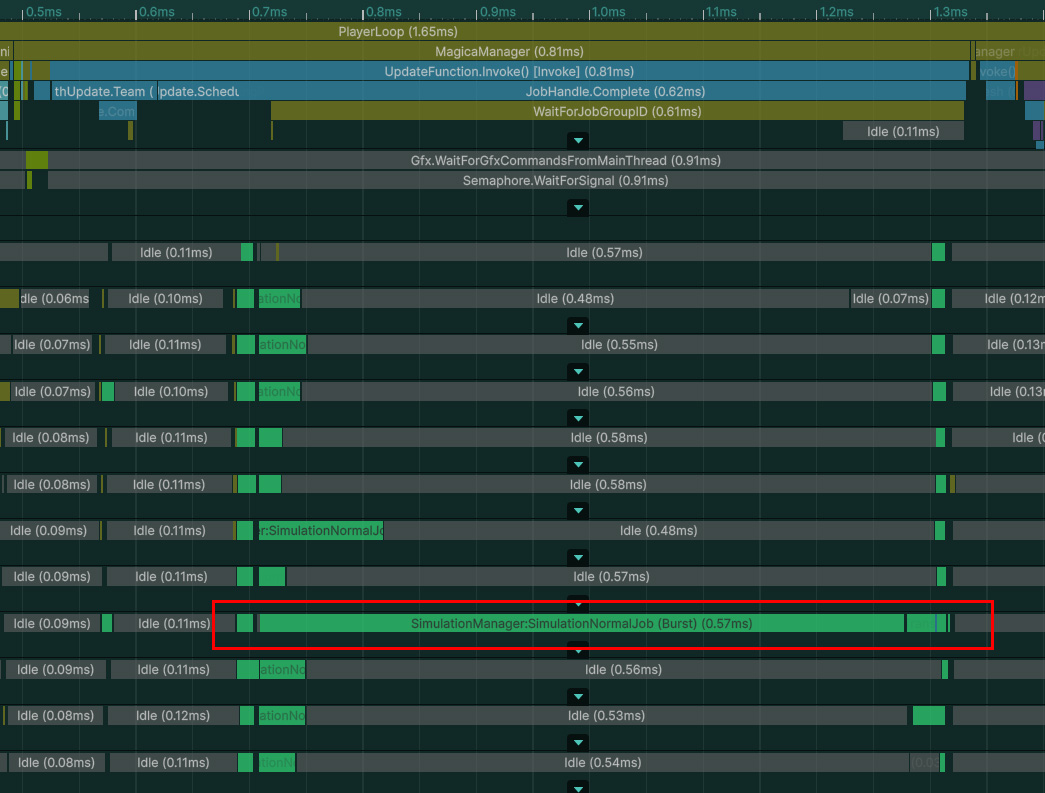
この重いジョブを処理する間、他のCPUコアが完全にアイドル状態になっている点に注目してください。
このような状況になるとCPUの効率が非常に悪くなり、分割ジョブより逆に時間がかかるような結果になってしまいます。
分割ジョブと一括ジョブの併用
この問題を解決するため、軽量なコンポーネントは一括ジョブで処理を行い、重いコンポーネントは分割ジョブで処理を行うハイブリッドシステムを実装しました。
これにより、CPUの無駄を省きコアを最大限活用できます。
一括ジョブと分割ジョブは並列実行されます。
分割ジョブが適用される条件は次の2つです。
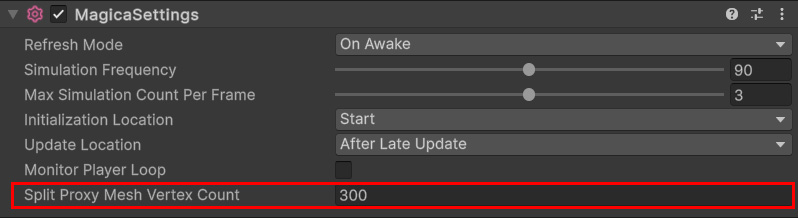
- プロキシメッシュの頂点数が300以上である
- セルフコリジョンもしくは相互コリジョンを利用している
この条件が1つでも該当する場合は、分割ジョブが採用されます。
プロキシメッシュの頂点数はインスペクターで確認が可能です。
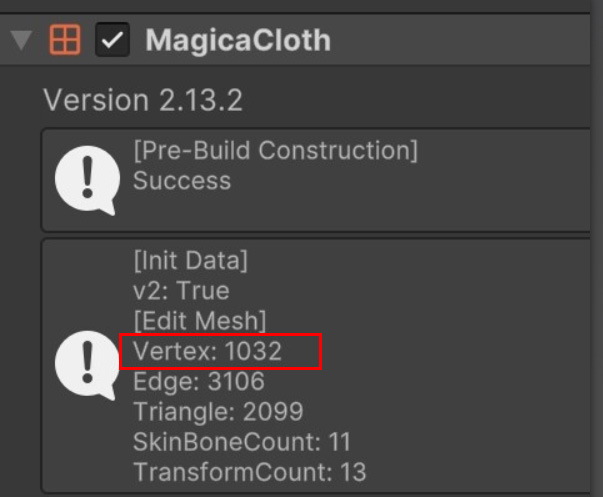
分割ジョブのしきい値の変更
分割ジョブの条件であるプロキシメッシュの頂点数は300となっていますが、このしきい値は変更することができます。
これには次の2つの方法があります。
MagicaSettings
MagicaSettingsコンポーネントを設置することで、コードなしで変更できます。
API
変更は実行中にいつでも可能です。
そのため最大の効率を目指すならば、プラットフォームに応じてしきい値を調整することも検討してみてください。
その他
エディタ環境での極端なパフォーマンスの低下について
これまでのところ、エンドユーザーからエディタ環境で実行する際に極端にパフォーマンスが低下するという報告がありました。
ビルド時に比べて数十倍の負荷が発生する模様です。
しかし、この問題は再現性がなく、また発生するのは一部のPC環境のみであることがわかっています。
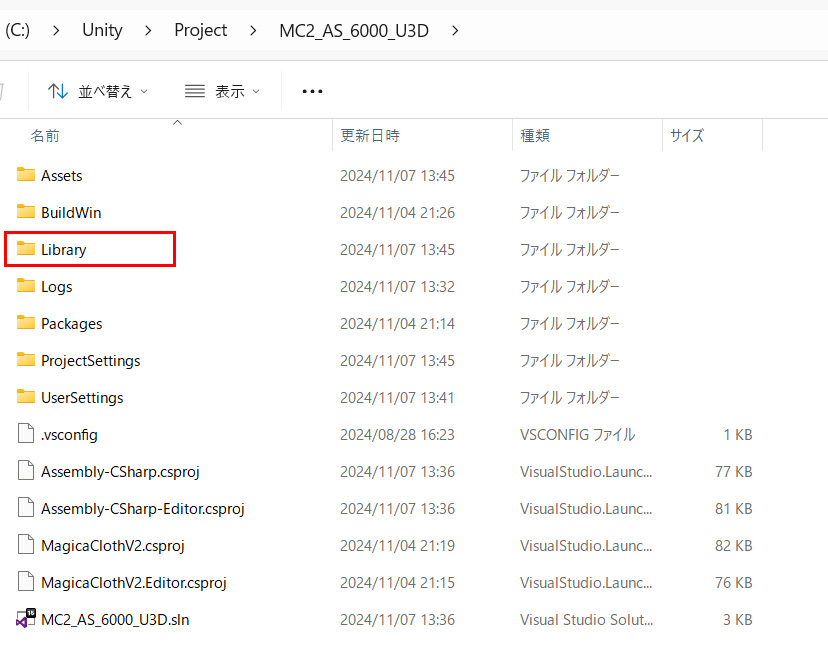
もし、このような状況が発生した場合は、次のようにプロジェクトのLibraryフォルダを削除してみてください。
一部のユーザーはこれで問題が解決したと報告しています。
Libraryフォルダはプロジェクトの作業用データが格納されており、削除しても再構築されます。
ただし、Libraryフォルダを削除する場合は、安全のため必ず次の手順で行うようにしてください。
- Unityエディタを終了させる
- プロジェクトのバックアップを取る
- Libraryフォルダを削除する
- Unityエディタを再起動する